「検索」はどう進化したのか―― 情報検索(IR)の現在地

AIの台頭により、検索は「リンクの羅列」から「統合された一つの答え」を提示するコンシェルジュへと進化した。第1回・第2回では今まさに進行しつつあるこの劇的なパラダイムシフトを提示したが、では、AIは膨大な情報の中から、何を基準に選んでいるのか? その仕組みを知ることは、“AIに選ばれるブランド設計”の第一歩になるはずだ。
連載第3回となる今回は、グローバルECの最前線を知るパベル・ザスラフスキー氏が、検索技術の歴史から最新のAIモデルまでを徹底解説。「語句の一致」から、意味、文脈理解、そして現在のマルチモーダルかつマルチベクトル検索へと至る過程をひも解く。(全6回)
●過去コラムはこちら!
【第1回】AI検索革命:EC事業者が直面する「検索から統合」への転換
【第2回】検索から会話へ:顧客はブランドに何を「プロンプト」するのか
検索の仕組みを理解する
近年、検索の形は大きく変化しています。かつては単語を並べて情報を探すのが一般的でしたが、現在では自然な文章で質問を入力する検索が当たり前になりつつあります。
では、検索エンジンや生成AIは、膨大な情報の中からどのようにして必要な情報を見つけ出しているのでしょうか。
AIは魔法の箱ではありません。その基盤にあるのは、Information Retrieval(IR:情報検索)と呼ばれる技術分野です。この分野では長年にわたり研究と実装が積み重ねられ、検索の仕組みは段階的に進化してきました。
生成AIに自社の情報が引用されるためには、現在の検索がどのような構造で情報を取得しているのかを理解しておくことが重要になります。
ここからは、検索技術がどのように進化してきたのか、その流れを整理して見ていきます。
検索が最初に直面した問題
初期の検索エンジンは、基本的に「単語の一致」を手がかりに情報を探していました。しかし、この方法にはすぐに限界が見えてきました。
例えば、ユーザーが「暖かい 冬用 コート」と検索しても、ページ側で「保温性の高い パーカー」と表現されている場合、検索エンジンは両者が同じ意味であることを理解できません。
つまり、内容が一致していても、使われている言葉が異なるだけで検索結果に表示されないという問題が起きていたのです。
この課題を解決するために、検索技術は大きく進化していきました。
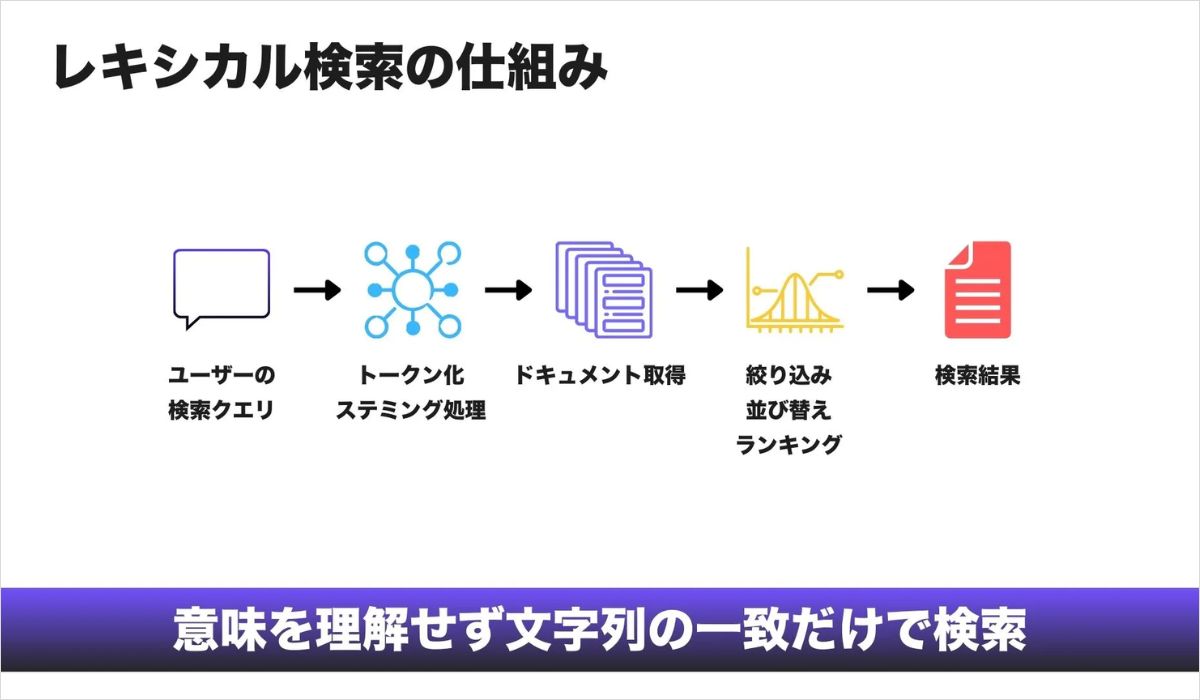
第1段階:「語句の一致」による検索
長い間、検索の中心はレキシカル検索でした。これは文字列をそのまま比較する検索方式で、ページ内にどの単語がどれだけ出現しているかを評価します。
たとえばユーザーが「西陣織 絹 着物」と検索すると、検索エンジンはその語句がページ内にどの程度含まれているかを調べ、関連度を判断します。このとき広く利用されていたアルゴリズムがBM25です。
BM25は、Term Frequency(単語の出現頻度)とInverse Document Frequency(その単語がどれだけ珍しいか)を組み合わせて、検索語とページ内容の関連性を算出します。
つまり、ある単語がページ内で頻繁に使われ、なおかつ他のページではあまり登場しないほど、そのページは検索語に対して関連性が高いと判断されていました。
第2段階:「意味」を扱う検索
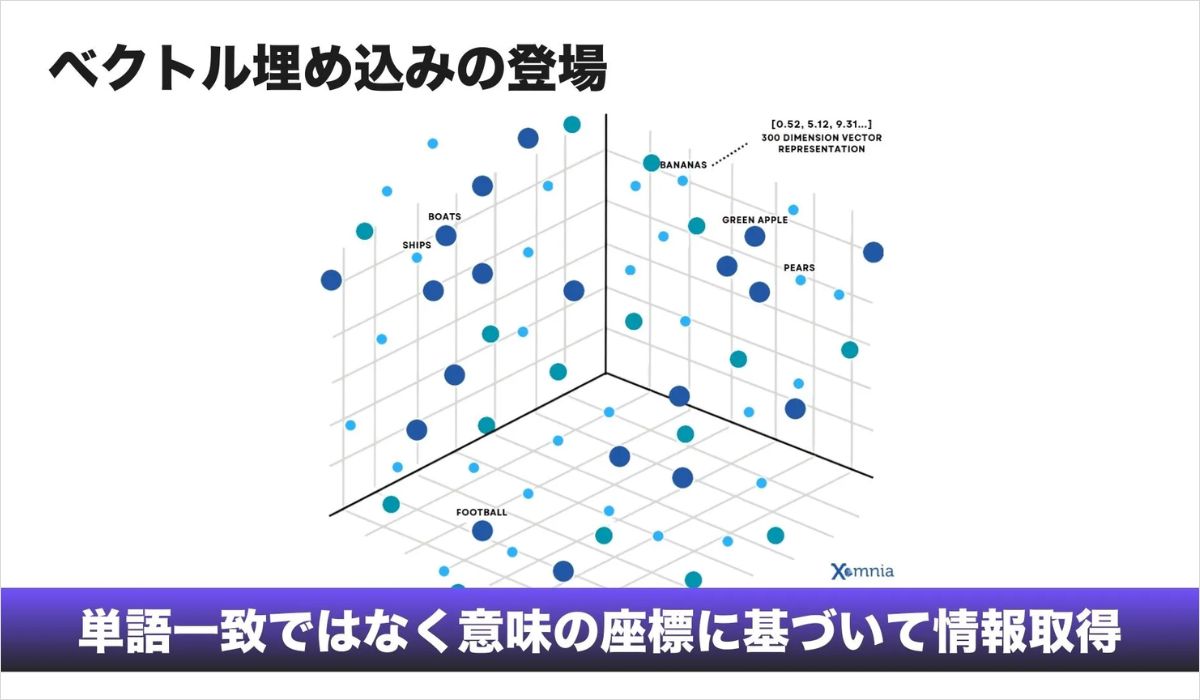
語句一致検索の問題を解決するために登場したのが、Embeddings(埋め込み表現)です。
埋め込みとは、単語や文章を数値ベクトルとして表現し、その意味の近さを空間上の距離として扱う方法です。言い換えると、単語を文字列としてではなく、意味を持つ位置情報として扱う仕組みです。
2013年に公開されたWord2Vecをきっかけに、単語は意味空間の中の点として表現されるようになりました。この空間では、「暖かい」と「保温性が高い」といった表現は互いに近い位置に配置されます。
重要なのは、この関係が人間が定義したルールではなく、大量のデータから自動的に学習されたものだという点です。この段階から、検索は語句一致ではなく意味の近さを基準に情報を取得するSemantic Search(意味検索)へと発展していきました。
第3段階:「文脈理解」の導入
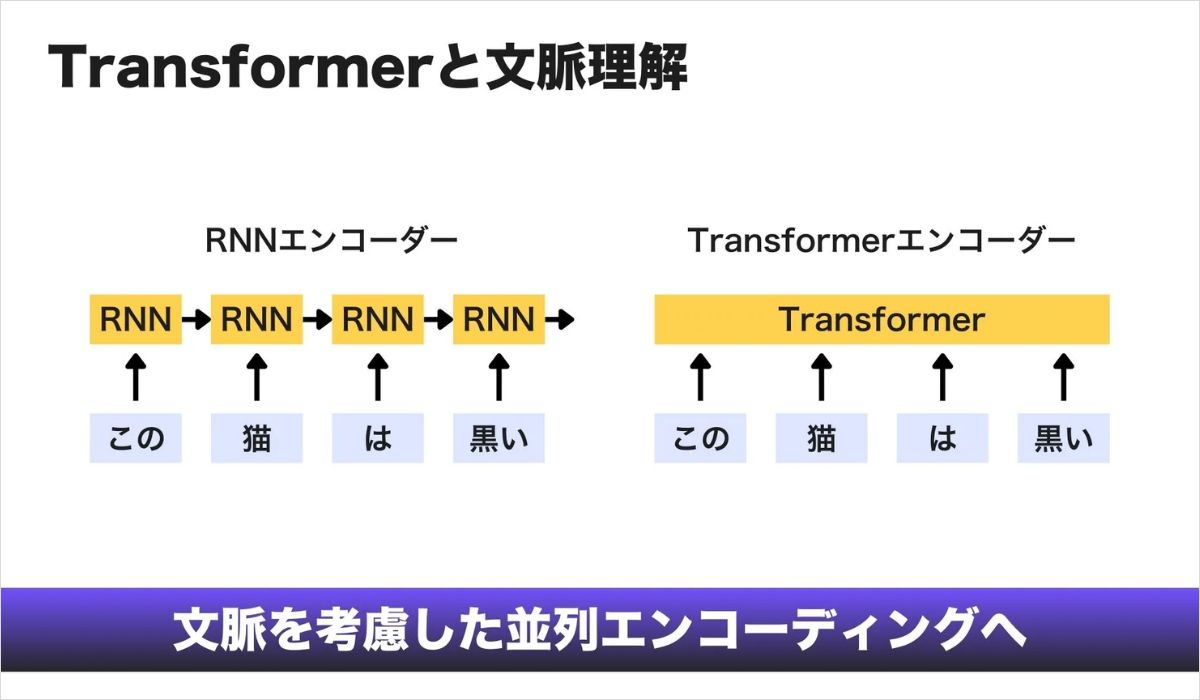
2017年に登場したTransformerは、検索理解をさらに大きく進化させました。
従来のモデルでは、文章は基本的に左から右へ順番に処理されていました。そのため、文の後半にある単語が前半の意味にどのように関係しているのかを十分に捉えることができませんでした。
Transformerは文章全体を同時に処理し、単語同士の関係性をまとめて評価します。この仕組みはSelf-Attention(自己注意機構)と呼ばれ、文章全体の文脈を踏まえた理解を可能にしました。
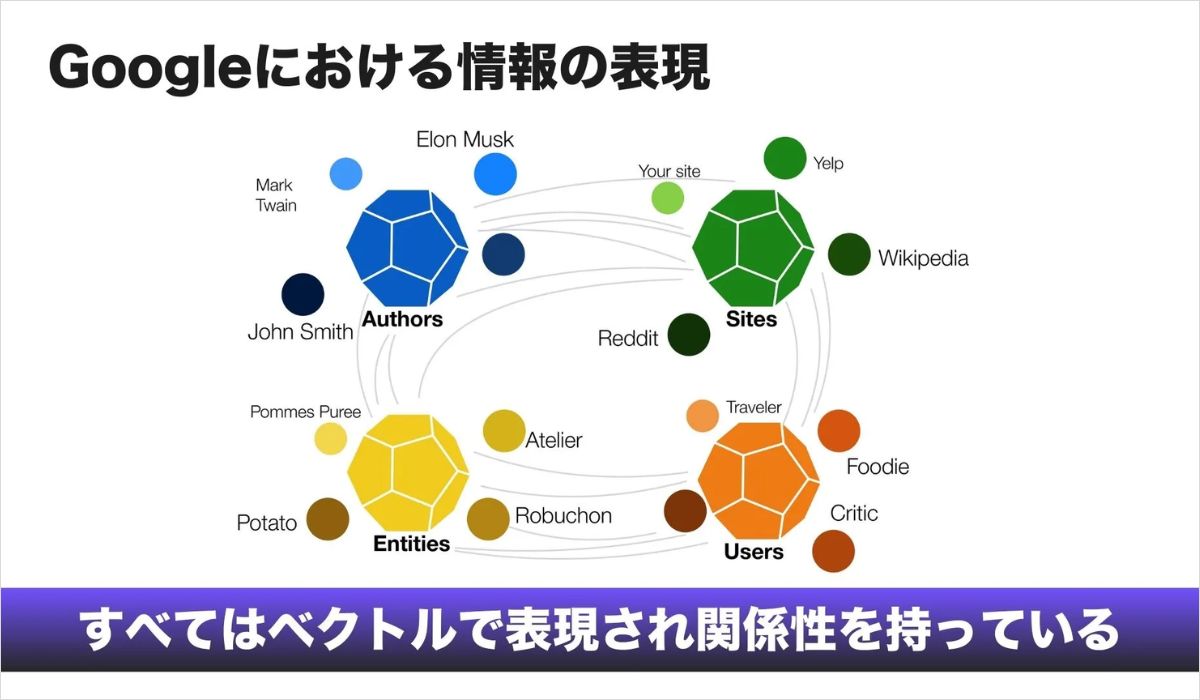
検索対象そのものもベクトル化される
現在の検索では、ベクトル化されるのは単語や文章だけではありません。
検索に関わるさまざまな対象が、高次元ベクトルとして表現されるようになっています。
■ウェブサイト埋め込み
検索エンジンは、ドメイン単位の埋め込みを作成し、サイト全体のトピックを理解します。たとえば日本の伝統陶芸について継続的に発信しているサイトは、その分野の意味空間の中で強い関連性を持つ位置に配置されます。
■著者埋め込み
著者の専門性や経験もベクトルとして表現されます。特定分野について継続的に発信している著者は、その領域に強い関連性を持つ情報源として評価されます。
■エンティティ埋め込み
Google Knowledge Graphでは、あらゆる対象がエンティティとして整理されています。エッフェル塔から特定ブランドの商品まで、これらは多言語かつマルチモーダルな情報としてベクトル化されています。
■ユーザー埋め込み
ユーザー自身も、検索履歴や行動データをもとにベクトルとして表現されます。そのため、同じ検索語であってもユーザーによって表示される結果が変わることがあります。
検索と生成を支えるAIモデル
現在の検索と生成AIの中心には、Transformerを基盤としたモデルがあります。
BERTは検索語の文脈を理解するためのモデルです。単語を前後両方向から読み取り、ユーザーの意図をより正確に解釈します。GPTは文章生成を担うモデルです。取得された情報を統合し、自然な回答として提示します。
簡潔に言えば、BERTはAIが情報を理解する役割を担い、GPTはそれを説明する役割を担っています。
●マルチモーダル理解の登場
検索はさらに進化し、現在では複数の情報形式を同時に扱えるようになっています。その代表例がMUM(Multitask Unified Model)です。MUMはテキストだけでなく、画像や複数言語を同時に理解することができます。
たとえば陶器の写真を見るだけで、その用途や歴史的背景を理解することができます。また、英語で入力された質問に対して、日本語の記事を参照しながら回答が生成されることもあります。
検索は「取得」から「生成」へ
現在の検索は、単にリンクの一覧を表示する仕組みではありません。
AIは次の3つのプロセスを通じて回答を作ります。
●関連する情報の断片を取得する
●品質が低い情報を除外する
●残った情報を統合して回答を生成する
このプロセスはGenerative Synthesis(生成的統合)と呼ばれます。
●ニューラル情報検索の時代
MUMの登場によって、言語やメディア形式の壁は大きく低くなりました。現在では75以上の言語を横断して情報が理解され、日本の事業者が発信した情報が海外ユーザーの回答として生成されることもあります。
このNeural IRの時代では、検索の基盤は完全に埋め込みへと移行しています。取得、ランキング、パーソナライズ、そして生成のすべてがこの仕組みによって支えられています。文字列の一致ではなく、意味の整合性が検索結果を左右する時代に入っているのです。
次回予告
次回は、ユーザーが検索を入力した瞬間から結果が表示されるまでの間に、検索エンジン内部でどのような処理が行われているのかを見ていきます。
「ギフトEC」をテーマに、ビームスやTENTIAL、ギフトモールなどが登壇します!
お席には限りがあるため、詳細・お申し込みは下記よりお早めに。

著者

Pavel Zaslavsky(パベル・ザスラフスキー)
イスラエル工科大学(Technion)MBAプログラムにて、eコマースおよびデジタルリテール分野を教える講師。20年以上にわたり、ECプラットフォーム、商品検索、商品カタログ管理、コンテンツ最適化といった領域において、実務と研究の双方に携わってきた。現在は、日本とイスラエルの共同スタートアップであるLISUTO株式会社のイスラエル拠点責任者(General Manager)としても、EC事業者向けコンテンツAIソリューションの企画・開発・グローバル展開を統括している。
これまでにeBayにてグローバルカタログオペレーションの創設者兼責任者を務め、世界各国のマーケットプレイスを横断する商品データ基盤を構築。また、Shopping.com(eBayグループ)では、ヨーロッパ全域のカタログオペレーションを立ち上げ、運用モデルを確立した。
その後も複数の大手EC多国籍企業においてアドバイザーとして参画し、商品データ設計、検索品質改善、業務オペレーションの高度化を支援。大学教育と実務の両面から、オンラインリテールにおけるAI活用とEC運営の進化を発信している。
■LISUTO株式会社について
https://ecnomikata.com/support_company/120/
■LISUTO株式会社 公式サイト
https://www.lisuto.co.jp/