AIは回答をどのように作るのか:大規模言語モデルの基本と違い

情報検索が「取得」から「生成」へと進化した今、AIは情報の断片を統合し答えを紡ぎ出す【回答者】となった。連載第3回では検索技術の進化と現在地を整理したが、では、AIは取得した膨大なデータをどう評価し、一つの答えへと仕立て上げているのか。
第4回となる今回は、グローバルECの最前線を知るパベル・ザスラフスキー氏が、AIの頭脳とサイト上の情報をつなぐ「RAG(検索拡張生成)」の仕組みを解説。Google、ChatGPTといった主要プラットフォームごとの設計思想の違いを比較し、自分たちのサイトが「引用」を勝ち取るための戦略をひも解く。(全6回)
●過去コラムはこちら!
【第1回】AI検索革命:EC事業者が直面する「検索から統合」への転換
【第2回】検索から会話へ:顧客はブランドに何を「プロンプト」するのか
【第3回】「検索」はどう進化したのか―― 情報検索(IR)の現在地
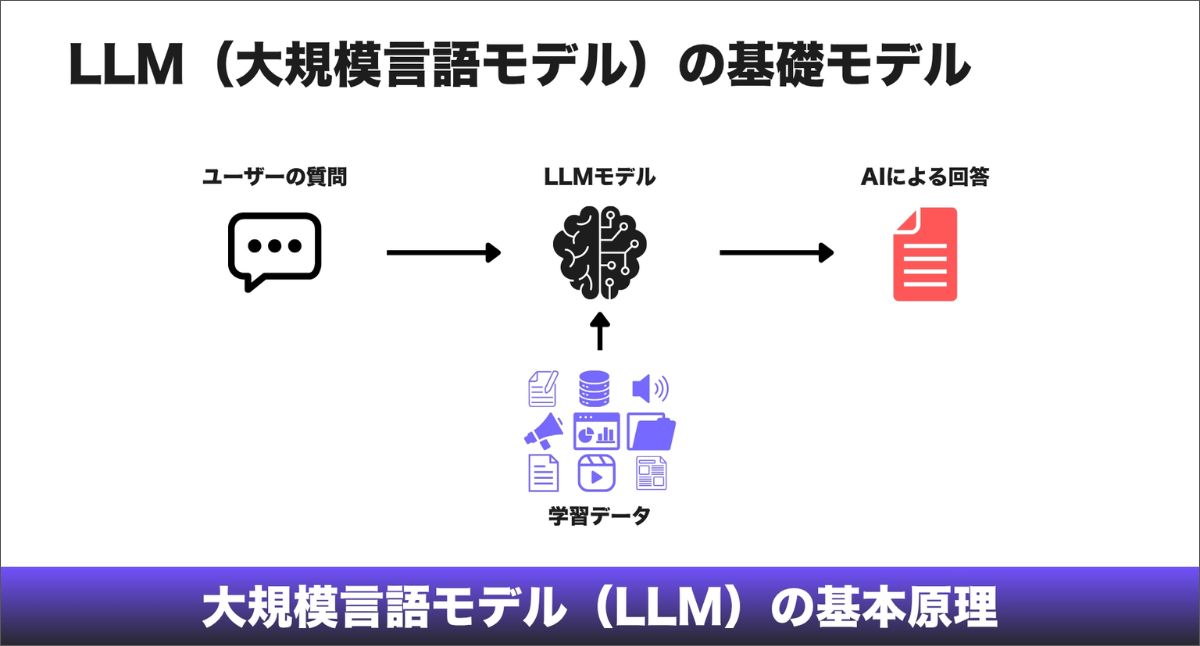
大規模言語モデルの基本原理
前回の記事では、検索が単語を照合するものから、埋め込み表現によって「世界をマッピングする」ものへと進化してきた流れを見てきました。今回は、AIが実際にどのようにして答えを組み立てているのかを見ていきます。
ChatGPTやGeminiのような大規模言語モデルは、本質的には高次元の予測エンジンです。データベースのように事実をそのまま保持しているのではなく、単語(トークン)同士がどのような関係で出現しやすいかという統計的な確率構造を学習しています。
顧客が大規模言語モデルに自社の商品について質問すると、モデルは、構築時に取り込まれた膨大なデータである「事前学習(Pre-training)」の内容をもとに答えを組み立てます。
EC事業者にとってのリスクはここにあります。大規模言語モデルが参照している事前学習データが古い場合、新しい春のコレクションや最近出店したばかりのお店などの最新情報は含まれていません。その結果、古い情報をもとに推測したり、もっともらしい誤った内容を生成したりすることがあります。
RAGインデックスを伴う大規模言語モデル
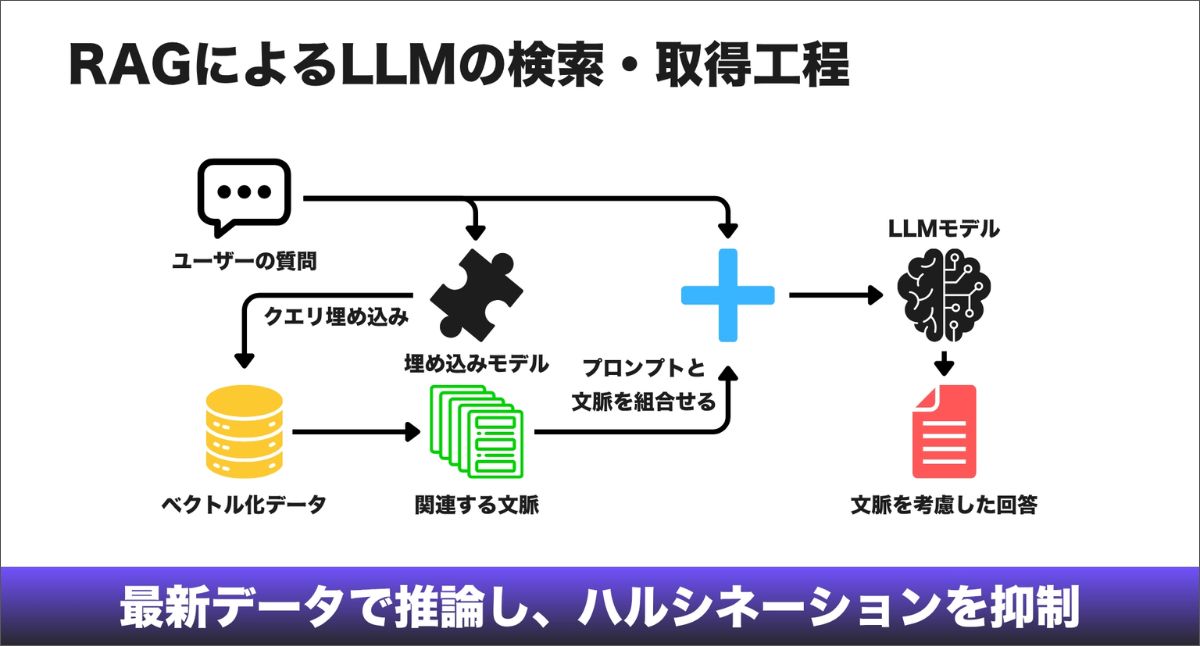
ここで状況を変えるのが、検索拡張生成(Retrieval-Augmented Generation、RAG)です。RAGは、大規模言語モデルの頭脳と、あなたのWebサイトにある最新の事実をつなぐ橋のようなものです。
たとえば、大規模言語モデルを試験を受ける学生だと考えてみてください。RAGがない場合、その学生は記憶だけを頼りに試験を受けています。RAGがある場合は、「教科書持ち込み可」の試験を受けている状態です。
1. 情報の取得(Retrieval):ユーザーが検索エンジンに質問すると、システムはまずあなたの「インデックス」、つまりWebサイトを見に行き、もっとも関連性の高い意味単位の情報、チャンク(Chunk)を探します。
2. 情報の補強(Augmentation):その特定のチャンクを「コンテキスト」として大規模言語モデルに渡します。
3. 生成(Generation):大規模言語モデルが、その事実だけをもとに答えを書きます。
RAGがあるからこそ、関連性設計(Relevance Engineering)が重要になります。あなたのWebサイトの文章が分かりにくかったり、AIにとって「読みにくい」構造だったりすると、その学生、つまり大規模言語モデルは、試験に受かるために必要な情報を得られません。
競争環境
すべてのAI検索プラットフォームが同じアーキテクチャを使っているわけではありません。市場で優位に立つには、主要なプラットフォームがそれぞれどのような考え方で動いているのかを理解する必要があります。
GoogleのAIによる概要とAIモードは、検索バーに追加された別アプリではありません。既存の検索そのものに組み込まれた、検索拡張型のレイヤーです。見た目は新しくても、土台にあるのはGoogleが長年かけて磨いてきた検索基盤であり、そこにGeminiの力が加わっています。
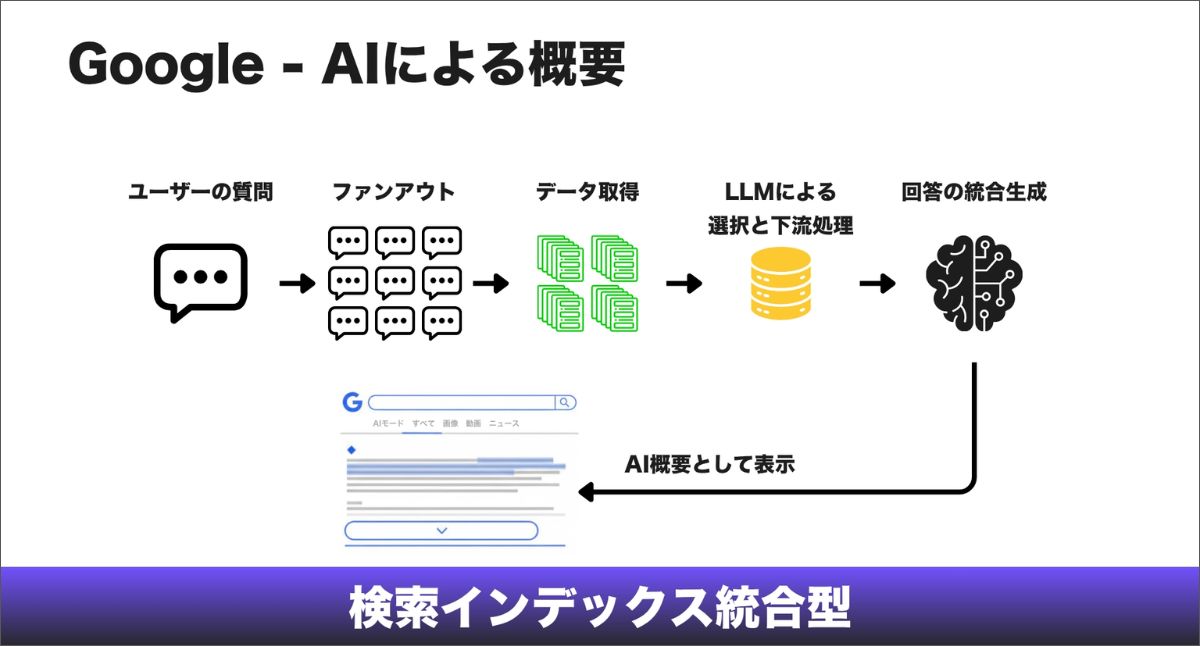
Googleに送られた検索クエリは、5つの異なる処理段階を通ります。
1. クエリ理解:システムは意味解析(セマンティック)を使い、単なるキーワードの一致を超えて、ブランド、場所、物体といった「エンティティ」を特定します。そのうえで、その質問がAIによる回答に適しているかどうかも判断します。健康や金融のような高リスク領域では、ここで特に慎重な扱いがされることがあります。
2. 質問の分解と同時並行探索(Fan Out):これは現代の検索を大きく拡張する仕組みです。AIは1つの質問を複数の並列サブクエリへと「爆発」させます。価格比較、ユーザーレビュー、技術仕様など、まだユーザーが聞いていない続きの質問まで先回りして考え、一度に調べにいきます。
3. 複数ソースからの情報取得:エンジンは何十億ものページ、知識グラフ(Knowledge Graph)、さらにはYouTubeの字幕まで横断して探索します。ここで探しているのは、順位付けの対象になる「ページ全体」ではありません。分解されたそれぞれのサブクエリに答えるための、最適なチャンクです。
4. 集約とフィルタリング:いわば「編集者」の工程です。システムは重複する情報を取り除き、経験・専門性・権威性・信頼性を示すE-E-A-Tで絞り込みます。さらに、要約に組み込みやすい、抽出しやすい断片を優先しています。
5. 大規模言語モデルによる統合:Geminiが、検証済みのチャンクを受け取り、それらを自然で一貫した文章にまとめ上げます。これは、あなたのWebサイトが学生に答えを与える「教科書持ち込み可」の試験です。
● AIによる概要は、検索を起点にしたRAGシステムです。引用を付けながら、検索結果ページ上で直接答えを返そうとします。
● AIモードは、より会話的な体験です。AIが質問の分解と同時並行探索(Query Fan-out)を行い、次に聞かれそうなことまで先回りします。
●Googleにおける小売の戦略では、信頼性(Trust)と引用実績(Citation)が通貨になります。Googleは、情報密度が高いソースを優先します。
Googleが巨大で持続的なWebインデックスを自前で維持しているのに対し、基本的なChatGPTモデルは「ライブ取得(Live Fetch)」の思想で動いています。モデル自体は静的なデータ群で学習されていますが、現代のWeb全体を頭の中に保持しているわけではありません。必要なときだけ棚を見に行く、高速な司書のような存在です。
リアルタイムパイプライン
ユーザーが質問を入力すると、ChatGPTは戦略的な検索クエリを複数生成し、それを外部のインデックスに送ります。主にBingですが、Googleや独自ソースも増えつつあります。そこで有望なURLの短い候補リストを取得し、その後の重要な段階として、それらのページ本文をリアルタイムで取得します。
この構造は、EC事業者にとって特有の障壁を生みます。答えの統合がその場でリアルタイムに行われるため、回答に含まれるかどうかは、その瞬間に取得できるかどうかに完全に依存します。
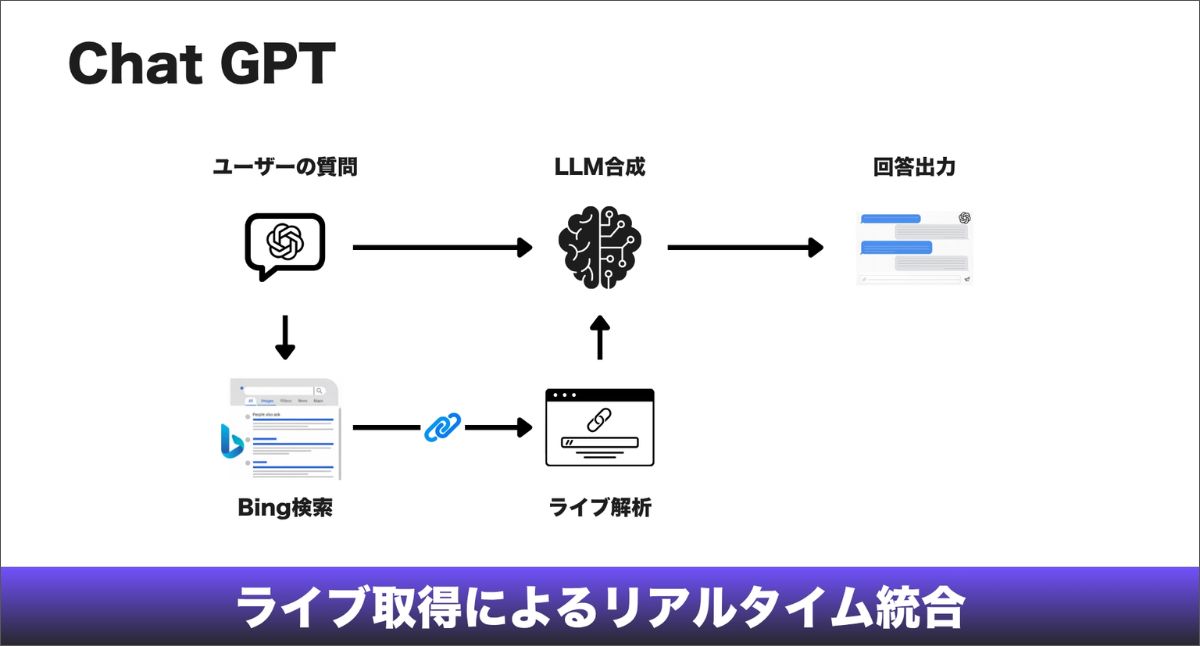
あなたのサイトに、次のような「取得の阻害要因(retrieval blockers)」がある場合、ChatGPTの目には、実質的に存在していないのと同じです。
●robots.txtの障壁:OAI-SearchBotをブロックしていると、答えが完璧に載っていても、ChatGPTはあなたを引用しません。
●JavaScriptの空白地帯:Googleは複雑なJavaScriptを読む能力を長年かけて高めてきましたが、ChatGPTのクローラーはクライアントサイドレンダリング(CSR)を苦手とすることがあります。商品情報がブラウザでページを読み込んだ後にしか現れない場合、AIには空白ページとしか見えていない可能性があります。
●速度遅延:サイトの応答が遅いと、AIの取得処理がタイムアウトすることがあります。RAGの世界では、遅いページは、眠っているページとして見られています。
●意味の不透明さ:見出しや本文がマーケティング的な飾り文句の中に埋もれていたり、代替テキスト(alt属性)のない画像に依存していたりすると、AIは統合に必要な「きれいな」テキストを抽出できません。
ChatGPTで勝つための戦略は、サイトを技術的に透明にすることです。もっとも重要な事実を、軽量で解析しやすいHTMLで届ける必要があります。このパイプラインでは、もっとも速く、もっとも明快なチャンクが引用を勝ち取ります。
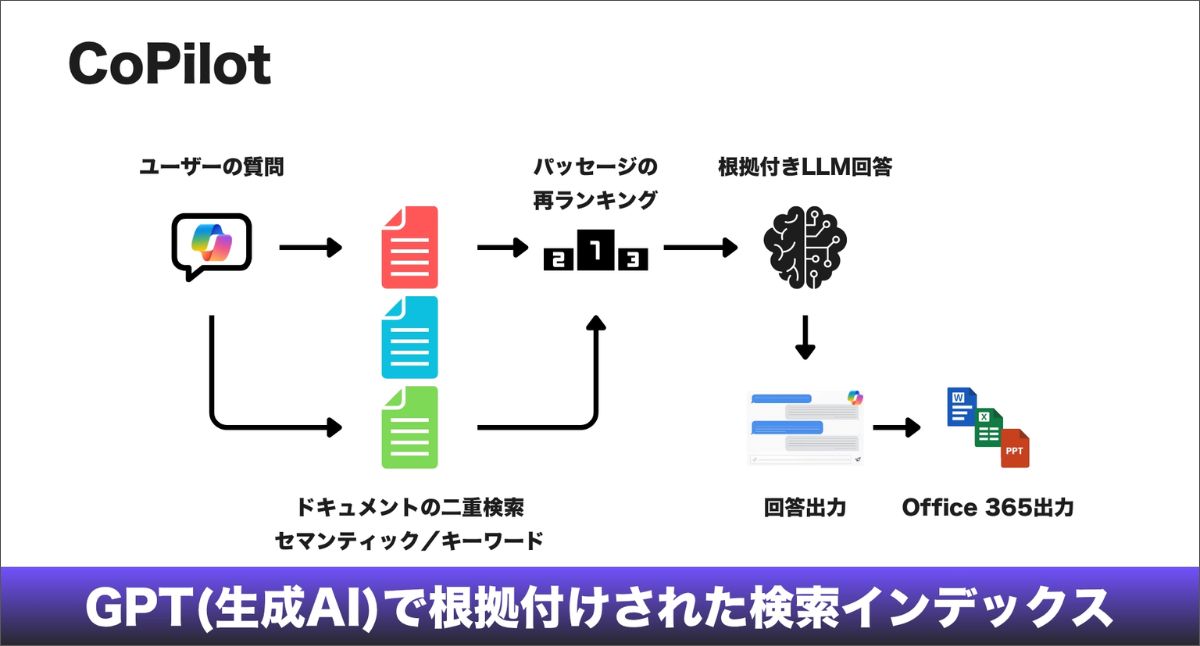
Microsoft Copilotは、生成AIのスーツを着た古典的な検索エンジンです。Copilotは、既存の実績あるBingのランキング基盤の上に直接構築されています。
EC事業者にとっての意味は明確です。従来のSEOシグナルは、依然として重要です。Copilotの世界では、まず通常のランキング競争で勝たなければ、「グラウンディングセット(回答の根拠となる情報群)」の候補にすら入りません。Bingで上位に入れなければ、大規模言語モデルが使う「教科書持ち込み可」の試験会場に到達できないのです。
業務利用における優位性
EC事業者にとっての独自性は、CopilotがMicrosoft 365と統合されていることです。CopilotはWord、Excel、Teamsの中に存在するため、あなたの商品データがそのままビジネス的な文脈に流れ込むことがあります。
たとえば、購買担当者がExcelの中でCopilotに「3種類のオフィスチェアを比較して」と尋ねると、あなたの商品データがそのまま表計算シートに引き込まれる可能性があります。
Copilotで勝つための戦略は、「表」と「リスト」に最適化することです。Copilotは、比較表へ変換しやすい構造化データを得意とします。商品仕様が会話的な文章の中に埋もれていると、ランキングには載れても、ユーザーの比較検討表の中で明確な選択肢として「引用」されることはありません。
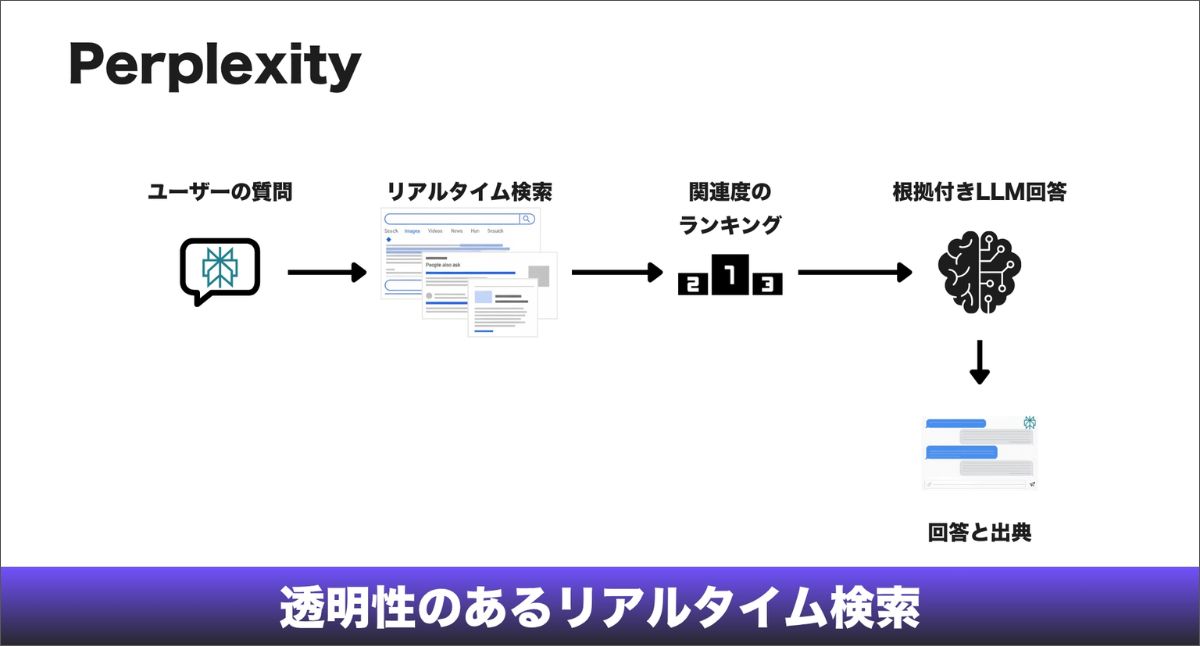
Perplexityは「発見エンジン」です。ほかと違って、最初に検索エンジンとして始まり、その後で大規模言語モデルを加えました。
違いは、Perplexityがソースを重視している点です。書くほぼすべての文に脚注のような引用を付けます。
小売の戦略として見ると、Perplexityは「引用を狙うハンター」です。ここに登場するには、そのテーマにおいて、あなたのコンテンツがもっとも権威ある根拠である必要があります。
次回予告
主要なプラットフォームに自社ブランドを「信頼できる情報源」として選んでもらいたいのであれば、自分たちをナレッジアーキテクトとして捉え始める必要があります。次回の記事では、Google AIによる概要のアーキテクチャと処理フローを、さらに深く見ていきます。

著者

Pavel Zaslavsky(パベル・ザスラフスキー)
イスラエル工科大学(Technion)MBAプログラムにて、eコマースおよびデジタルリテール分野を教える講師。20年以上にわたり、ECプラットフォーム、商品検索、商品カタログ管理、コンテンツ最適化といった領域において、実務と研究の双方に携わってきた。現在は、日本とイスラエルの共同スタートアップであるLISUTO株式会社のイスラエル拠点責任者(General Manager)としても、EC事業者向けコンテンツAIソリューションの企画・開発・グローバル展開を統括している。
これまでにeBayにてグローバルカタログオペレーションの創設者兼責任者を務め、世界各国のマーケットプレイスを横断する商品データ基盤を構築。また、Shopping.com(eBayグループ)では、ヨーロッパ全域のカタログオペレーションを立ち上げ、運用モデルを確立した。
その後も複数の大手EC多国籍企業においてアドバイザーとして参画し、商品データ設計、検索品質改善、業務オペレーションの高度化を支援。大学教育と実務の両面から、オンラインリテールにおけるAI活用とEC運営の進化を発信している。
■LISUTO株式会社について
https://ecnomikata.com/support_company/120/
■LISUTO株式会社 公式サイト
https://www.lisuto.co.jp/