AI概要の内側:クエリはどのように処理されるのか

AIが情報を「統合」し、ユーザーの求める答え紡ぎ出す裏側では、従来のアルゴリズムとは一線を画すプロセスが動いている――。
イスラエル工科大学MBAプログラムでeコマース分野を教えるパベル・ザスラフスキー氏が、現在急速に進む“AI検索革命”の中で「EC事業者が今、知っておくべきこと」を掘り下げる本連載。第5回となる今回は、Google AIの「頭脳の内側」へとさらに踏み込み、自社のデータがたどる旅路を明らかにする。(全6回)
●過去コラムはこちら!
【第1回】AI検索革命:EC事業者が直面する「検索から統合」への転換
【第2回】検索から会話へ:顧客はブランドに何を「プロンプト」するのか
【第3回】「検索」はどう進化したのか―― 情報検索(IR)の現在地
【第4回】AIは回答をどのように作るのか:大規模言語モデルの基本と違い
リンクの照合 vs. 意味の統合
前回の議論では、AI検索における「誰が」「何を」という問いを探りました。今回は、Google AIの"頭脳"の内側に踏み込んでいきます。
これまで、Googleの「上位10件」という予測可能な仕組みに慣れ親しんできた方も多いでしょう。しかし、AI概要(AI Overviews)の時代へと移行しつつある今、Googleの"ルール"は、これまでより予測しにくいものになっています。
―――――
この20年間、Googleのアプローチは取得中心型(Retrieval-centric)でした。その役割は、入力されたキーワードに最もマッチするページを見つけ出すことでした。答えを組み立てる労力は、ユーザー側に委ねられていました。つまり、リンクを自ら探してクリックし、自分で情報を統合するという行動です。
新しいアプローチは統合中心型(Synthesis-centric)です。Googleはもはや単なる"図書館員"ではなく、"分析者"として機能します。商品リストを提示するのではなく、「なぜその商品が他より優れているのか」を説明し、購入先まで案内することを目指しています。この転換は、クエリを裏側でどのように処理するかという、技術的な変化を必要とします。
ステップ1:クエリの理解——意図の分類と推測の技法
ユーザーがプロンプトを入力したとき、Googleが最初に行うのは、その文章を分解し、「何が本当に問われているのか」を理解することです。
●意図の分類(Intent Classification)
システムはまず、プロンプトをカテゴリに振り分けます。これは「ナビゲーション」意図(特定のショップを探している)なのか、「情報収集」意図(商品やテーマについて学びたい)なのか、それとも「購買」意図(今すぐ買いたい)なのか。そして、そのクエリが「AI概要に適しているか」を判断します。
●条件の特定(Slot Identification)
AIは、ユーザーのリクエストに含まれる条件を一つひとつ拾い上げます。たとえば「幅広甲高の足に合う、軽量ランニングシューズで15,000円以内」というプロンプトがあれば、AIは次の条件を特定します――[商品:シューズ] [用途:ランニング] [重さ:軽量] [フィット:幅広] [価格:15,000円以下]。
重要なのは、自社の商品ページや説明文がこれらの条件(素材・サイズ・用途・価格帯など)を明確に記載していない場合、AIが候補として拾い上げられずに弾かれてしまう、という点です。
●書き換えと多様化(Rewrites and Diversifications)
Googleが探索するのは、ユーザーが入力した文字列だけではありません。入力クエリを複数のバリエーションに書き換え、見落としがないよう探索します。「幅広甲高」に対して「4E」や「リラックスフィット」といった同義語や関連概念も含め、選択肢を広げます。
●先読みのサブ質問(Speculative Sub-Questions)
これはAIの「想像力」にあたります。ユーザーが次に必要とするであろう問いを先取りして生成します。たとえば高級カメラを検索した場合、AIは「レンズの互換性」「旅行時のバッテリー持続時間」「日本国内での保証サポート」といった問いも先回りして考えます。
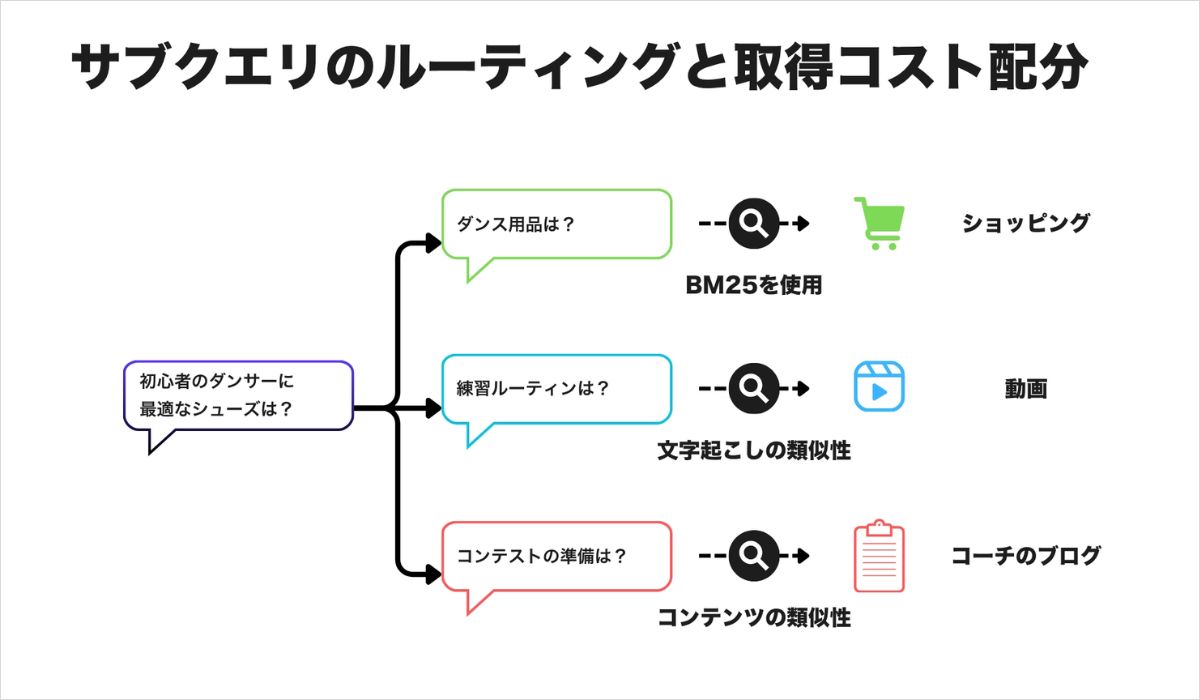
ステップ2:情報の取得戦略——並行探索と読み込みコスト
AIが1つのプロンプトを10前後のサブクエリへと展開すると、次に決めるのは「どこに送るか」です。
●サブクエリとソースの対応付け
すべてのサブクエリが同じ送り先に向かうわけではありません。「ユーザーレビュー」に関するサブクエリはGoogleマップや専門フォーラムへ、「技術仕様」に関するクエリは商品ページへ、「ビジュアルスタイル」に関するクエリはGoogle画像検索やYouTubeへと振り分けられます。EC事業者として重要なのは、自社ブランドがこれらすべてのソース別に存在感を持っていることです。
●読み込みコストと優先順位(Cost Budgeting)
AI検索には、Google側に相当の計算コストが発生します。このコストを管理するため、システムは「最も抵抗の少ない経路」――つまり表示が速く、解析しやすく、答えを含む可能性が高いソースを優先します。サイトの表示が遅かったり、構造が複雑だったりすると、AIがそのページを読み込む前に別のソースへ移ってしまうことがあります。
ステップ3:統合のための選択
Googleは情報の「候補セット」を収集し終えました。今度は、最終的なAI応答に織り込むに値する特定の情報を選定します。ここで重要になるのが、関連性の設計です。
●情報の密度と抽出のしやすさ
AIが評価するのは、"情報の密度"です。「東京で一番のショップです!」という宣伝文句が9割で、「24時間配送に対応」という事実が1割しかない文章は、密度が低いと判断されます。AIが好むのは、すべての語が具体的かつ検証可能な事実を担い、要約に抽出しやすい文章です。
●スコープの明確さと適用可能性
その情報はサブクエリに対して具体的に答えているか。AIが「夏の通気性」を探しているときに、あなたのページが「オールシーズン対応の快適さ」を謳っているだけでは、スコープが曖昧だと判断されます。AIは、ユーザーの特定条件(たとえば「日本の夏の湿度」)にフィットするデータを求めています。
●権威性と鮮度のバランス
Googleは、そのブランドが特定のジャンルで"信頼できる発信源"として認識されているかを評価しています。加えて、安定性と鮮度のバランスも見ています。商品価格には「鮮度」(当日のデータ)が求められ、素材や製法に関する情報には「安定性」(長期にわたる権威ある情報)が求められます。
●安全フィルター
最後に、すべての情報は安全審査を通過する必要があります。確立された事実に反するもの、安全基準に違反するものはすべて除外されます。どれほど関連性が高いコンテンツであっても、この審査を通過できなければ採用されません。
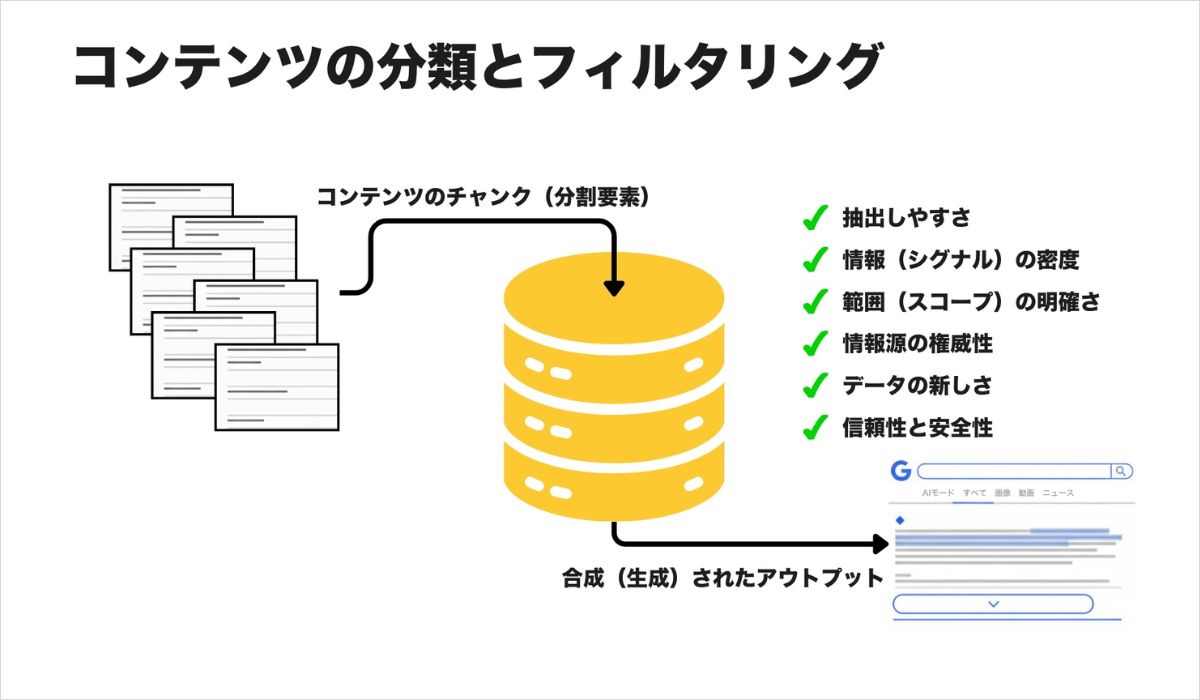
まとめ:最終統合フローの全体像
Google AIの概要に選ばれ、可視性を維持するためには、自社データがたどる旅路を理解する必要があります。
プロンプトの入力(Prompt Entry): ユーザーが自然言語でリクエストを入力する。
意図の展開(Intent Expansion): Googleがリクエストの背後にある「なぜ」を掘り下げる。
→ 商品名だけでなく「誰が・なぜ買うか」を説明文に盛り込むことが重要になる。
並行探索(Fan-Out):システムが複数の検索を同時に起動する。
→ レビュー・仕様・画像など、複数の接点でブランドが登場できることが前提になる。
情報の取得とフィルタリング(Retrieval & Filtering):表示が速く、機械が読みやすく、権威ある情報が優先的に選ばれる。
→ 商品スペック・素材・使用シーンを、明確な文章で記載することが選ばれる条件になる。
生成による統合(Generative Synthesis):AIが、最も有用な情報を提供したソースを引用しながら、カスタムの回答を生成する。
→ 引用されるのは「一番売れているページ」ではなく「一番答えているページ」である。
アクション
Googleに引用されるページとは、キーワードを並べたページではなく、ユーザーの問いに対して具体的・明確・正確に答えられるページです。商品説明・ブランドストーリー・FAQ――これらすべてが、AIの回答候補になり得ます。
「上位表示」の対象は、もはやトップページだけではありません。自社ブランドが持つあらゆる具体的な知識が、その対象になります。
このクエリフローを理解することで、「キーワード対策」から「情報の設計」へと発想を転換できます。自社サイトを、AIが答えを探しに来たときに迷わず引用できる、精度の高い情報の集合体として設計してください。
―――――
最終回となる次回では、EC事業者として、AI概要の中で引用・言及されるために実践すべき戦略と戦術を振り返ります。

著者

Pavel Zaslavsky(パベル・ザスラフスキー)
イスラエル工科大学(Technion)MBAプログラムにて、eコマースおよびデジタルリテール分野を教える講師。20年以上にわたり、ECプラットフォーム、商品検索、商品カタログ管理、コンテンツ最適化といった領域において、実務と研究の双方に携わってきた。現在は、日本とイスラエルの共同スタートアップであるLISUTO株式会社のイスラエル拠点責任者(General Manager)としても、EC事業者向けコンテンツAIソリューションの企画・開発・グローバル展開を統括している。
これまでにeBayにてグローバルカタログオペレーションの創設者兼責任者を務め、世界各国のマーケットプレイスを横断する商品データ基盤を構築。また、Shopping.com(eBayグループ)では、ヨーロッパ全域のカタログオペレーションを立ち上げ、運用モデルを確立した。
その後も複数の大手EC多国籍企業においてアドバイザーとして参画し、商品データ設計、検索品質改善、業務オペレーションの高度化を支援。大学教育と実務の両面から、オンラインリテールにおけるAI活用とEC運営の進化を発信している。
■LISUTO株式会社について
https://ecnomikata.com/support_company/120/
■LISUTO株式会社 公式サイト
https://www.lisuto.co.jp/